Our research is focused on constructing condensed representations from data streams. These representations are updated with every new instance that arrives and are explicitely designed to support reasoning over the entire data stream. One of their main building blocks are online density estimators that can be manipulated by inference algorithms and, therefore, provide a means to extract relevant information from it. By combining these inference algorithms, one can also perform more complex tasks such as pattern mining.
Many of these ideas are realized in the MiDEO framework (Mining Density Estimates inferred Online), which is explained in more detail below.
Density Estimation
In order to model joint probability distributions, we employed so-called classifier chains and a set of probabilistic online classifiers. The overall chain aims to model the dependencies among the features, and the classifiers in a chain aim to model the probabilities of a particular feature, where the individual estimates are combined using the product rule. To increase the robustness of the estimate, we also proposed variants that use ensembles of classifier chains and ensembles of weighted classifier chains, where the estimate is computed from a set of classifier chains (usually 10).
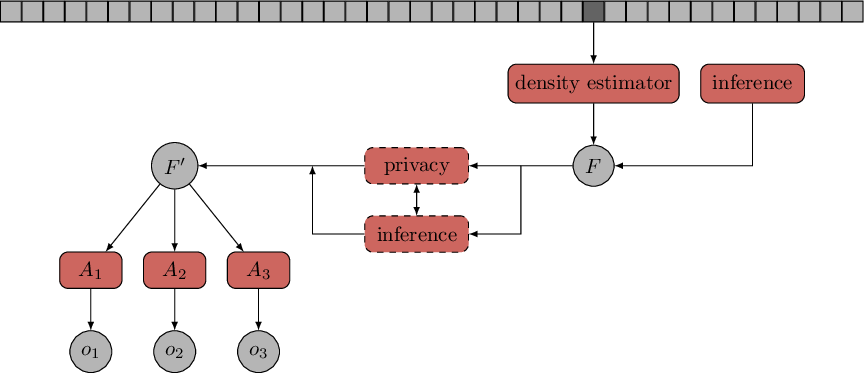
The density estimates, however, are not only designed to estimate the probability distribution of the data stream, but enable inference tasks to manipulate the estimate and, thereby, extracting relevant information from it. This is useful to answer questions about the data distribution of the stream and can also be used to perform complex data mining tasks such as pattern mining (see below).
If the data stream consists of many variables, this approach is easily pushed to its limits. Therefore, we also designed an online density estimator for data of higher dimensionality. The main idea is to project the data stream into a lower dimensional space, estimating the density there, and then performing a back translation.
Read more: Online Estimation of Discrete Densities, Online Density Estimation of Heterogeneous Data Streams in Higher Dimensions, Online Estimation of Discrete, Continuous, and Conditional Joint Densities using Classifier Chains
Probabilistic Condensed Representation
With the introduction of probabilistic condensed representations of data, we propose a novel way of performing data mining. Traditional data mining algorithms operate on the data itself, which poses problems in stream settings, where the amount of data is often too large to be kept in memory. Established data stream solutions try to avoid memory limitations by pursuing window-based approaches. However, they implicitly assume that collecting the data and performing the data mining task is either happening simultaneously or with a small temporal delay. Hence, the user has to know in advance, i.e., before collecting the data, whether she wants to perform a certain data mining task – something which is unrealistic in interactive environments where data streams may need to be analyzed after days or even weeks. For example, after performing pattern mining, she discovers that the patterns contained in a particular subset of the data would be interesting. A window-based solutions would require to initiate another pattern mining process and to wait for new data instances to arrive. To overcome these limitations, we propose the MiDEO framework (Mining Density Estimates inferred Online), in which stream mining is no longer performed on original data in any form (e.g., windows, random samples, ...) but on online density estimates providing an estimate of the joint density of the data stream. These density estimates are extended by inference capabilities, so that users are able to preprocess the data beforehand (e.g., selecting a subset of the data or specifying already known information, querying, ...).
To demonstrate the effectiveness of the framework, we designed two itemset mining algorithms: one for density estimate supporting a basic set of inference operations and one that is specifically designed for density estimates consisting of classifier chains of Hoeffding trees.
Read more: A Probabilistic Condensed Representation of Data for Stream Mining, Privacy-Preserving Pattern Mining on Online Density Estimates
Privacy
When mining data, one is looking for general patterns. But the more specific they become, the smaller is the set of data instances that match the pattern and the higher is the risk that confidential information is disclosed. This risk is already lowered when, instead of the data, only statistical information is used, but confidential information can still be disclosed using inference. The same applies to probabilistic condensed representations of data that we proposed. To alleviate this problem, we designed algorithms to achieve k-anonymity and t-closeness for online density estimates, which means that small groups of entities are protected that can be easily identified based on characteristic properties.
Read more: Privacy-Preserving Pattern Mining on Online Density Estimates
Recurrent Data Distributions
As with many data stream applications, the distribution of the stream is usually not fixed but subject to changes. Although the online density estimates that we proposed are able to adapt to these changes, they can still only represent the current state. All information originating from historical data is simply lost, which unfortunately prevents a detailed analysis of the data stream. To overcome this limitation, we extended the current framework to model all the distributions of the data stream. Since data distribution can also be recurrent, we additionally provided mechanisms to identify recurrent density estimates and recurrent parts of densities.
Read more: Modeling Recurrent Distributions in Streams using Possible Worlds
Publications
- Michael Geilke, Andreas Karwath, Eibe Frank and Stefan
Kramer
Online Estimation of Discrete, Continuous, and Conditional Joint Densities using Classifier Chains
In: Data Mining and Knowledge Discovery, Springer 2017. doi:10.1007/s10618-017-0546-6. - Michael Geilke and Stefan Kramer
Privacy-Preserving Pattern Mining on Online Density Estimates
In: Proceedings of the International Conference on Big Knowledge (ICBK 2017), IEEE 2017. doi:10.1109/ICBK.2017.32, Bibtex, presentation. - Michael Geilke, Andreas Karwath, and Stefan Kramer
Online Density Estimation of Heterogeneous Data Streams in Higher Dimensions
In: Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases (ECML-PKDD 2016), pages 65-80, Springer 2016. doi:10.1007/978-3-319-46128-1_5, Bibtex, preprint, presentation. - Michael Geilke, Andreas Karwath, and Stefan Kramer
Modeling Recurrent Distributions in Streams using Possible Worlds
In: Proceedings of the International Conference on Data Science and Advanced Analytics 2015 (DSAA 2015), pages 1-9, IEEE 2015. doi:10.1109/DSAA.2015.7344814, Bibtex, preprint, presentation. - Michael Geilke, Andreas Karwath, and Stefan Kramer
A Probabilistic Condensed Representation of Data for Stream Mining
In: Proceedings of the International Conference on Data Science and Advanced Analytics 2014 (DSAA 2014), pages 297-303, IEEE 2014. doi:10.1109/DSAA.2014.7058088, Bibtex, preprint, presentation. - Michael Geilke, Andreas Karwath, Eibe Frank, and Stefan Kramer
Online Estimation of Discrete Densities
In: Proceedings of the 13th IEEE International Conference on Data Mining (ICDM 2013), pp. 191-200, IEEE 2013. doi:10.1109/ICDM.2013.91, Bibtex, preprint, presentation. - Michael Geilke and Sandra Zilles
Polynomial-Time Algorithms for Learning Typed Pattern Languages
In: Proceedings of the 6th International Conference on Language and Automata Theory and Applications (LATA 2012), Lecture Notes in Computer Science 7183, pages 277-288, Springer 2012. doi:10.1007/978-3-642-28332-1_24, Bibtex, presentation. - Michael Geilke and Sandra Zilles
Learning Relational Patterns
In: Proceedings of the 22nd International Conference on Algorithmic Learning Theory (ALT 2011), Lecture Notes in Artificial Intelligence 6925, pages 84-98, Springer 2011. doi:10.1007/978-3-642-24412-4, Bibtex, presentation.
(Co)-Reviewing
- Journal of Computer and System Sciences
- ECML/PKDD: European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (2012 - 2017)
- KDD: ACM SIGKDD Conference on Knowledge Discovery and Data Mining (2013 - 2017)
- ICDM: IEEE International Conference on Data Mining (2013 - 2017)
- DSAA: International Conference on Data Sciences and Advanced Analytics (2014)
- AAAI Conference on Artificial Intelligence (2013)
- EDBT: International Conference on Extending Database Technology (2012)